3.2. Specular IBL
LearnOpenGL - PBR - IBL - Specular IBL
Specular IBL
이전 장에서는 PBR을 이미지 기반 조명(IBL)과 결합하여 간접적인 난반사(diffuse) 조명 부분으로 사용할 복사조도 맵(irradiance map) 을 사전 계산하는 방법을 설정했다. 이번 장에서는 반사 방정식의 스펙큘러(specular) 부분을 다룰 것이다:
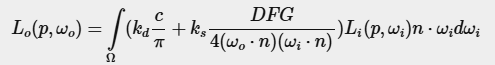
위 식을 보면, 쿡-토랜스(Cook-Torrance) 모델의 스펙큘러 항( ksk_sks 로 곱해지는 부분)은 적분 내에서 일정하지 않으며, 입사광 방향뿐만 아니라 뷰 방향에도 의존한다.
모든 가능한 입사광 방향과 뷰 방향을 포함하여 이 적분을 해석적으로 풀려고 하면 조합(combinatorial)이 기하급수적으로 증가하여 실시간 계산이 불가능할 정도로 비용이 많이 든다. 이에 대해 에픽 게임즈(Epic Games) 는 몇 가지 타협점을 감수하면서도 실시간 처리가 가능한 스펙큘러 사전 컨볼루션 기법을 제안했으며, 이를 "스플릿 섬 근사(Split Sum Approximation)" 라고 한다.
스플릿 섬 근사 방법에서는 반사 방정식의 스펙큘러 부분을 두 개의 독립적인 항으로 나누어 각각 컨볼루션을 수행한 후, PBR 셰이더에서 이 두 항을 결합하여 스펙큘러 간접 이미지 기반 조명(Specular IBL) 을 계산할 수 있도록 한다.
이전의 복사조도 맵을 사전 컨볼루션했던 것과 유사하게, 스플릿 섬 근사에서는 HDR 환경 맵을 입력으로 사용하여 스펙큘러 반사를 컨볼루션해야 한다. 이 개념을 명확히 이해하기 위해, 다시 한번 반사 방정식을 살펴보되 이번에는 스펙큘러 부분에 집중해보자.
 복사조도 컨볼루션(irradiance convolution)과 동일한 성능상의 이유로, 우리는 이 적분의 스펙큘러 부분을 실시간으로 해결하는 것이 불가능하며, 실용적인 성능을 기대할 수도 없다. 이상적인 접근 방식은 이 적분을 사전 계산하여 "스펙큘러 IBL 맵(specular IBL map)"을 생성한 후, 이 맵을 프래그먼트의 노멀로 샘플링하는 것이다.
복사조도 컨볼루션(irradiance convolution)과 동일한 성능상의 이유로, 우리는 이 적분의 스펙큘러 부분을 실시간으로 해결하는 것이 불가능하며, 실용적인 성능을 기대할 수도 없다. 이상적인 접근 방식은 이 적분을 사전 계산하여 "스펙큘러 IBL 맵(specular IBL map)"을 생성한 후, 이 맵을 프래그먼트의 노멀로 샘플링하는 것이다.
그러나 이 과정에서 문제가 발생한다. 복사조도 맵을 사전 계산할 수 있었던 이유는 적분이 입사 방향( ωi\omega_iωi ) 에만 의존했고, 상수인 난반사 알베도(diffuse albedo) 항을 적분 바깥으로 이동할 수 있었기 때문이다. 반면, 이번 적분의 BRDF(Bidirectional Reflectance Distribution Function) 는 다음과 같이 표현된다:
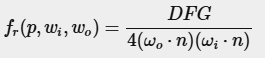
여기서 적분은 입사 방향 ωi\omega_iωi 뿐만 아니라 출사 방향 ωo\omega_oωo 에도 의존한다. 하지만 사전 계산된 큐브맵을 두 개의 방향 벡터로 샘플링하는 것은 현실적으로 불가능하다. 이전 장에서 설명했듯이, 위치 ppp 는 이 문제에서 중요하지 않다. 그렇다고 모든 가능한 ωi\omega_iωi 및 ωo\omega_oωo 조합에 대해 적분을 사전 계산하는 것은 실시간 렌더링에서 비효율적이다.
에픽 게임즈(Epic Games) 는 이 문제를 해결하기 위해 적분을 두 개의 독립적인 부분으로 분할하여 사전 계산한 후, PBR 셰이더에서 결합하는 방법을 제안했다. 이를 "스플릿 섬 근사(Split Sum Approximation)" 라고 한다.
이 방법에서는 반사 방정식의 스펙큘러 적분을 다음과 같이 두 개의 적분으로 분리한다:
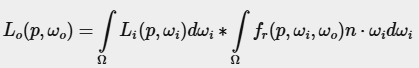
첫 번째 적분 (컨볼루션이 적용된 부분) 은 "사전 필터링된 환경 맵(Pre-filtered Environment Map)" 이라 불리며, 이는 복사조도 맵과 유사한 사전 계산된 환경 컨볼루션 맵이다. 하지만 이번에는 표면의 거칠기(roughness)를 고려해야 한다.
거칠기가 증가할수록, 환경 맵은 더 넓은 영역의 샘플 벡터를 사용하여 컨볼루션되며, 결과적으로 반사가 더 흐려진다. 이 과정을 위해 각 거칠기 값에 대해 컨볼루션을 수행하며, 그 결과를 Mipmap 레벨 에 저장한다. 예를 들어, 특정 환경 맵이 5개의 서로 다른 거칠기 값을 반영하는 사전 컨볼루션 결과를 5개의 Mipmap 레벨에 저장한다고 가정하면, 그 구조는 다음과 같다:

우리는 쿡-토랜스 BRDF(Cook-Torrance BRDF)의 법선 분포 함수(NDF, Normal Distribution Function) 를 사용하여 샘플 벡터와 그 산란 정도(scattering amount) 를 생성한다.
그러나 환경 맵을 컨볼루션하는 과정에서는 뷰 방향(view direction)을 미리 알 수 없다. 따라서 Epic Games는 추가적인 근사를 적용하여, 뷰 방향(및 스펙큘러 반사 방향)이 출력 샘플 방향 ωo\omega_oωo 와 동일하다고 가정한다.
이를 코드로 표현하면 다음과 같다:
vec3 N = normalize(w_o);
vec3 R = N;
vec3 V = R;
이 방식에서는 사전 필터링된 환경 컨볼루션 과정에서 뷰 방향을 고려할 필요가 없다.
그러나 이러한 근사는 경사(grazing) 각도에서의 스펙큘러 반사가 정확하지 않게 표현되는 문제를 초래한다. 즉, 비스듬한 각도에서 보는 스펙큘러 반사가 실제보다 약하게 보이는 현상이 발생한다.
아래 이미지는 이 현상을 보여준다 (Moving Frostbite to PBR 논문에서 제공):

스플릿 섬 방정식의 두 번째 부분은 스펙큘러 적분의 BRDF 부분과 같다.
만약 들어오는 복사휘도가 모든 방향에서 완전히 흰색(L(p,x) = 1.0)이라고 가정하면, 입력된 거칠기와 법선 n 및 광원 방향 ωi 간의 각도(n⋅ωi)에 대한 BRDF의 응답을 사전 계산할 수 있다.
Epic Games는 사전 계산된 BRDF의 응답을 다양한 거칠기 값과 법선 및 광원 방향 조합에 대해 2D 조회 텍스처(LUT)에 저장하며, 이를 BRDF 적분 맵이라고 한다.
2D 조회 텍스처는 표면의 프레넬 응답을 위한 스케일(빨강) 및 바이어스(초록) 값을 출력하여 스플릿 스펙큘러 적분의 두 번째 부분을 제공한다.

우리는 평면의 가로 텍스처 좌표(0.0에서 1.0 범위)를 BRDF의 입력 값 n⋅ωi로, 세로 텍스처 좌표를 입력된 거칠기 값으로 취급하여 조회 텍스처를 생성한다.
이 BRDF 적분 맵과 사전 필터링된 환경 맵을 사용하여 두 가지를 결합하면 스펙큘러 적분의 결과를 얻을 수 있다.
float lod = getMipLevelFromRoughness(roughness);
vec3 prefilteredColor = textureCubeLod(PrefilteredEnvMap, refVec, lod);
vec2 envBRDF = texture2D(BRDFIntegrationMap, vec2(NdotV, roughness)).xy;
vec3 indirectSpecular = prefilteredColor * (F * envBRDF.x + envBRDF.y);
이제 Epic Games의 스플릿 섬 근사법이 반사 방정식의 간접 스펙큘러 부분을 대략적으로 어떻게 접근하는지 개요를 살펴보았다. 이제 우리가 직접 사전 컨볼루션된 부분을 구축해 보자.
Pre-filtering an HDR environment map
환경 맵을 사전 필터링하는 과정은 조도 맵을 컨볼루션하는 방식과 매우 유사하다. 차이점은 거칠기를 고려하고, 사전 필터링된 맵의 MIP 레벨에 점진적으로 거칠어진 반사를 저장한다는 점이다.
우선, 사전 필터링된 환경 맵 데이터를 저장할 새로운 큐브 맵을 생성해야 한다. MIP 레벨을 위한 충분한 메모리를 할당하려면 glGenerateMipmap을 호출하여 필요한 메모리를 쉽게 할당할 수 있다.
unsigned int prefilterMap;
glGenTextures(1, &prefilterMap);
glBindTexture(GL_TEXTURE_CUBE_MAP, prefilterMap);
for (unsigned int i = 0; i < 6; ++i)
{
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, 0, GL_RGB16F, 128, 128, 0, GL_RGB, GL_FLOAT, nullptr);
}
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glGenerateMipmap(GL_TEXTURE_CUBE_MAP);
사전 필터링된 맵의 MIP 맵을 샘플링할 계획이므로, 최소화 필터를 GL_LINEAR_MIPMAP_LINEAR로 설정하여 삼중 선형 필터링(trilinear filtering)을 활성화해야 한다. 기본 MIP 레벨에서 사전 필터링된 스펙큘러 반사는 각 면당 128×128 해상도로 저장된다. 이는 대부분의 반사에 충분하지만, 차량 반사처럼 부드러운 재질이 많은 경우 해상도를 높이는 것이 좋다.
이전 챕터에서는 환경 맵을 컨볼루션할 때 구면 좌표계를 사용하여 반구(Ω)에 균등하게 분포된 샘플 벡터를 생성했다. 이는 조도(Irradiance) 계산에는 적절하지만, 스펙큘러 반사 계산에는 비효율적이다.
스펙큘러 반사의 경우 표면의 거칠기에 따라 빛이 반사 벡터 r을 중심으로 좁게 또는 넓게 반사되며, (표면이 극도로 거칠지 않는 한) 반사 벡터를 중심으로 분포하는 특성을 가진다.

가능한 출사 광 반사의 일반적인 형태를 스펙큘러 로브(specular lobe) 라고 한다. 표면의 거칠기가 증가할수록 스펙큘러 로브의 크기도 증가하며, 입사 광 방향이 달라짐에 따라 스펙큘러 로브의 형태도 변한다. 즉, 스펙큘러 로브의 형태는 재질에 따라 크게 달라진다.
마이크로 서피스 모델(microsurface model)에서 스펙큘러 로브는 특정 입사 광 방향에 대해 마이크로패싯 하프웨이 벡터(microfacet halfway vector) 를 중심으로 반사되는 것으로 볼 수 있다. 대부분의 광선이 마이크로패싯 하프웨이 벡터를 중심으로 반사되는 경향이 있기 때문에, 샘플 벡터를 유사한 방식으로 생성하는 것이 합리적이다. 그렇지 않으면 대부분의 샘플이 낭비될 것이다.
이러한 과정을 중요도 샘플링(importance sampling) 이라고 한다.
Monte Carlo integration and importance sampling
중요도 샘플링을 완전히 이해하려면 먼저 몬테카를로 적분(Monte Carlo Integration)이라는 수학적 개념을 살펴볼 필요가 있다. 몬테카를로 적분은 주로 통계(statistics)와 확률 이론(probability theory)을 기반으로 한다. 이는 전체 모집단(population)의 모든 요소를 고려하지 않고도 특정 통계적 값이나 특징을 추정하는 방법이다.
예를 들어, 한 국가의 모든 시민의 평균 키를 알고 싶다고 가정하자. 이를 정확히 계산하려면 모든 시민의 키를 측정한 후 평균을 내야 한다. 하지만 대부분의 나라에서 인구 수는 상당히 많기 때문에, 이는 현실적으로 불가능한 접근 방식이다. 너무 많은 시간과 노력이 필요하기 때문이다.
대신, 모집단에서 완전히 무작위(unbiased)로 선택된 작은 하위 집합(subset)을 뽑아 해당 그룹의 키를 측정하고 평균을 내는 방법이 있다. 예를 들어, 100명의 시민만을 측정한다고 해도, 이 값은 실제 값에 가까운 근사치를 제공할 수 있다. 물론 완전히 정확하지는 않지만, 현실적으로 충분한 정밀도를 가질 수 있다.
이러한 개념을 대수의 법칙(Law of Large Numbers)이라고 하며, 이는 무작위로 뽑은 N개의 샘플이 충분히 많다면, 모집단의 실제 평균과 가까운 값을 얻게 된다는 원리다. 즉, 샘플 개수 N이 증가할수록 결과는 실제 값에 더욱 근접하게 된다.
몬테카를로 적분은 이 대수의 법칙을 활용하여 적분을 계산하는 방식이다. 일반적으로 적분을 수행할 때 모든 가능한 x 값(이론적으로 무한한 개수)을 계산하는 대신, 임의로 선택된 N개의 샘플 값만을 사용하여 평균을 구하는 방식을 적용한다. 샘플 개수 N이 증가할수록 적분 값은 실제 값에 더욱 가까워진다.
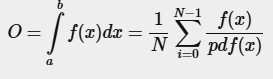
적분을 해결하기 위해 우리는 a에서 b까지 모집단에서 N개의 무작위 샘플을 뽑아 합산하고, 총 샘플 수로 나누어 평균을 구한다. pdf는 확률 밀도 함수(probability density function)를 나타내며, 특정 샘플이 전체 샘플 집합에서 발생할 확률을 알려준다. 예를 들어, 모집단의 키에 대한 pdf는 다음과 같을 것이다.
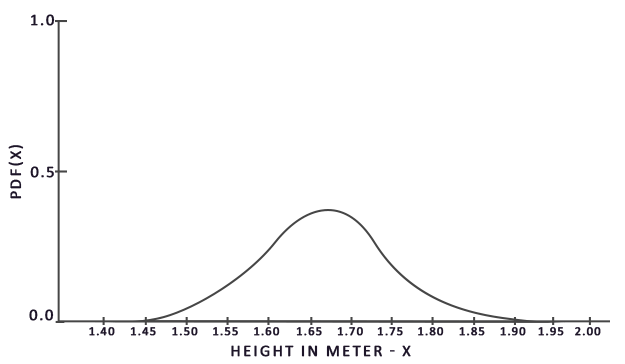
이 그래프에서 우리는 모집단의 무작위 샘플을 뽑을 때, 1.70의 키를 가진 샘플을 뽑을 확률이 1.50의 키를 가진 샘플을 뽑을 확률보다 더 높다는 것을 알 수 있다.
몬테카를로 적분에서 일부 샘플은 다른 샘플보다 더 높은 확률로 생성될 수 있다. 그렇기 때문에 일반적인 몬테카를로 추정에서는 샘플 값을 pdf에 따라 샘플 확률로 나누거나 곱한다. 지금까지 우리가 적분을 추정한 경우에서 생성된 샘플은 모두 균등 분포였으며, 즉 생성될 확률이 동일했다. 지금까지의 추정은 편향되지 않았으므로 샘플 수가 증가할수록 결국 적분의 정확한 해로 수렴할 것이다.
그러나 일부 몬테카를로 추정기는 편향되며, 이는 생성된 샘플이 완전히 무작위가 아니라 특정 값이나 방향으로 집중된다는 것을 의미한다. 이 편향된 몬테카를로 추정기는 더 빠른 수렴 속도를 가지며, 더 빠르게 정확한 해로 수렴할 수 있지만, 편향된 특성으로 인해 정확한 해에 도달하지 못할 가능성이 크다. 이는 컴퓨터 그래픽스에서는 일반적으로 받아들여지는 절충안이다. 왜냐하면 정확한 해가 중요하지 않으며, 결과가 시각적으로 허용 가능한 한 충분하기 때문이다. 우리는 곧 중요 샘플링(편향된 추정기를 사용하는 기법)에서 볼 수 있듯이, 생성된 샘플들이 특정 방향으로 편향되며, 이를 샘플마다 해당 pdf로 나누거나 곱하는 방식으로 처리한다.
몬테카를로 적분은 컴퓨터 그래픽스에서 널리 사용된다. 이는 연속적인 적분을 이산적이고 효율적인 방식으로 근사하는 직관적인 방법이다. 어떤 면적/부피(예: 반구 Ω)에서 샘플을 생성하고, 그 면적/부피 내에서 N개의 무작위 샘플을 생성하여, 모든 샘플 기여도를 합산하고 가중치를 부여하여 최종 결과를 얻는다.
몬테카를로 적분은 방대한 수학적 주제이므로 더 이상 세부 사항에 대해서는 다루지 않겠지만, 무작위 샘플을 생성하는 방법에는 여러 가지가 있다. 기본적으로 각 샘플은 우리가 익숙한 대로 완전히 (의사)무작위로 생성되지만, 반무작위 시퀀스의 특정 속성을 활용하면 여전히 무작위적이지만 흥미로운 속성을 가진 샘플 벡터를 생성할 수 있다. 예를 들어, 저불일치 시퀀스(low-discrepancy sequences)라고 불리는 것에 대해 몬테카를로 적분을 수행할 수 있는데, 이는 여전히 무작위 샘플을 생성하지만 각 샘플이 더 고르게 분포된다는 특징이 있다(이미지 제공: James Heald).
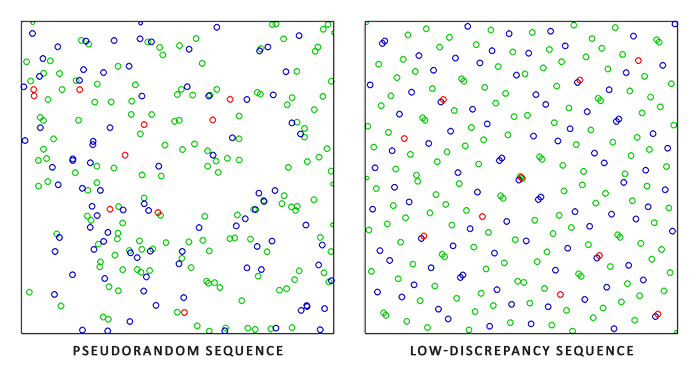
저불일치 시퀀스를 사용하여 몬테카를로 샘플 벡터를 생성할 때, 이 과정은 준 몬테카를로 적분(Quasi-Monte Carlo integration)이라고 합니다. 준 몬테카를로 방법은 더 빠른 수렴 속도를 가지므로 성능이 중요한 애플리케이션에서 흥미롭습니다.
몬테카를로 및 준 몬테카를로 적분에 대한 새로 얻은 지식을 바탕으로, 더 빠른 수렴 속도를 위해 사용할 수 있는 흥미로운 특성이 있습니다. 그것은 바로 중요 샘플링(importance sampling)입니다. 우리는 이전에 이 장에서 언급했지만, 빛의 반사에서 반사된 빛 벡터는 표면의 거칠기에 의해 결정된 크기를 가진 스페큘러 로브(specular lobe) 내에 제한됩니다. 스페큘러 로브 외부에서 생성된 샘플은 스페큘러 적분과는 관련이 없으므로, 샘플 생성을 스페큘러 로브 내로 집중하는 것이 의미가 있습니다. 이때 몬테카를로 추정기가 편향되는 대가를 치르게 됩니다.
이것이 본질적으로 중요 샘플링의 개념입니다: 마이크로페셋의 중간 벡터를 중심으로 거칠기에 의해 제한된 영역 내에서 샘플 벡터를 생성하는 것입니다. 준 몬테카를로 샘플링과 저불일치 시퀀스를 결합하고 중요 샘플링을 통해 샘플 벡터를 편향시키면, 높은 수렴 속도를 얻을 수 있습니다. 우리는 더 빠르게 해결책에 도달하므로 충분히 근사된 해를 얻기 위해 필요한 샘플 수가 상당히 줄어듭니다.
A low-discrepancy sequence
저불일치 시퀀스 이번 장에서는 준 몬테카를로 방법을 기반으로 랜덤 저불일치 시퀀스를 사용하여 간접 반사율 방정식의 스페큘러 부분을 미리 계산할 것입니다. 우리가 사용할 시퀀스는 Holger Dammertz가 신중하게 설명한 Hammersley 시퀀스입니다. Hammersley 시퀀스는 Van Der Corput 시퀀스를 기반으로 하며, 이 시퀀스는 십진수 이진 표현을 십진점 주위로 반영합니다.
몇 가지 비트 트릭을 사용하면, 셰이더 프로그램에서 Van Der Corput 시퀀스를 효율적으로 생성할 수 있으며, 이를 통해 Hammersley 시퀀스 샘플 i를 전체 샘플 수 N에 대해 얻을 수 있습니다:
float RadicalInverse_VdC(uint bits)
{
bits = (bits << 16u) | (bits >> 16u);
bits = ((bits & 0x55555555u) << 1u) | ((bits & 0xAAAAAAAAu) >> 1u);
bits = ((bits & 0x33333333u) << 2u) | ((bits & 0xCCCCCCCCu) >> 2u);
bits = ((bits & 0x0F0F0F0Fu) << 4u) | ((bits & 0xF0F0F0F0u) >> 4u);
bits = ((bits & 0x00FF00FFu) << 8u) | ((bits & 0xFF00FF00u) >> 8u);
return float(bits) * 2.3283064365386963e-10; // / 0x100000000
}
// ----------------------------------------------------------------------------
vec2 Hammersley(uint i, uint N)
{
return vec2(float(i)/float(N), RadicalInverse_VdC(i));
}
GLSL Hammersley 함수는 전체 샘플 집합 크기 N에 대해 저불일치 샘플 i를 제공합니다.
Hammersley sequence without bit operator support
모든 OpenGL 관련 드라이버가 비트 연산자(예: WebGL 및 OpenGL ES 2.0)를 지원하는 것은 아니므로, 비트 연산자에 의존하지 않는 Van Der Corput 시퀀스의 대체 버전을 사용할 수 있습니다:
float VanDerCorput(uint n, uint base)
{
float invBase = 1.0 / float(base);
float denom = 1.0;
float result = 0.0;
for(uint i = 0u; i < 32u; ++i)
{
if(n > 0u)
{
denom = mod(float(n), 2.0);
result += denom * invBase;
invBase = invBase / 2.0;
n = uint(float(n) / 2.0);
}
}
return result;
}
// ----------------------------------------------------------------------------
vec2 HammersleyNoBitOps(uint i, uint N)
{
return vec2(float(i)/float(N), VanDerCorput(i, 2u));
}
이 버전은 GLSL 루프 제한으로 인해 가능한 32비트를 모두 반복합니다. 성능은 낮지만, 비트 연산자가 없는 하드웨어에서도 작동합니다.
GGX Importance sampling
적분의 반구 Ω에서 균일하거나 무작위(Monte Carlo) 샘플 벡터를 생성하는 대신, 우리는 표면의 거칠기를 기반으로 마이크로 표면 반사 방향에 대해 편향된 샘플 벡터를 생성합니다. 샘플링 프로세스는 이전에 본 것과 유사합니다: 큰 루프를 시작하고, 무작위(저불일치) 시퀀스 값을 생성하고, 이 시퀀스 값을 사용해 접선 공간에서 샘플 벡터를 생성한 후, 월드 공간으로 변환하고 씬의 방사선을 샘플링합니다. 다른 점은 이제 저불일치 시퀀스 값을 입력으로 사용해 샘플 벡터를 생성한다는 것입니다:
const uint SAMPLE_COUNT = 4096u;
for(uint i = 0u; i < SAMPLE_COUNT; ++i)
{
vec2 Xi = Hammersley(i, SAMPLE_COUNT);
또한, 샘플 벡터를 구축하려면 샘플 벡터를 특정 표면 거칠기의 스페큘러 로브(specular lobe) 방향으로 지향하고 편향시킬 방법이 필요합니다. 우리는 이론 장에서 설명한 NDF를 사용하고 Epic Games에서 설명한 구면 샘플 벡터 프로세스에서 GGX NDF를 결합할 수 있습니다:
vec3 ImportanceSampleGGX(vec2 Xi, vec3 N, float roughness)
{
float a = roughness*roughness;
float phi = 2.0 * PI * Xi.x;
float cosTheta = sqrt((1.0 - Xi.y) / (1.0 + (a*a - 1.0) * Xi.y));
float sinTheta = sqrt(1.0 - cosTheta*cosTheta);
// from spherical coordinates to cartesian coordinates
vec3 H;
H.x = cos(phi) * sinTheta;
H.y = sin(phi) * sinTheta;
H.z = cosTheta;
// from tangent-space vector to world-space sample vector
vec3 up = abs(N.z) < 0.999 ? vec3(0.0, 0.0, 1.0) : vec3(1.0, 0.0, 0.0);
vec3 tangent = normalize(cross(up, N));
vec3 bitangent = cross(N, tangent);
vec3 sampleVec = tangent * H.x + bitangent * H.y + N * H.z;
return normalize(sampleVec);
}
이 코드는 거칠기와 저불일치 시퀀스 값 Xi를 기반으로 예상되는 마이크로 표면의 반사 벡터 방향으로 일부 편향된 샘플 벡터를 제공합니다. Epic Games는 Disney의 원래 PBR 연구에 기반하여 더 나은 시각적 결과를 위해 거칠기를 제곱하여 사용한다는 점에 유의하세요.
저불일치 Hammersley 시퀀스와 샘플 생성이 정의되었으므로, 이제 사전 필터 컨볼루션 쉐이더를 완성할 수 있습니다:
#version 330 core
out vec4 FragColor;
in vec3 localPos;
uniform samplerCube environmentMap;
uniform float roughness;
const float PI = 3.14159265359;
float RadicalInverse_VdC(uint bits);
vec2 Hammersley(uint i, uint N);
vec3 ImportanceSampleGGX(vec2 Xi, vec3 N, float roughness);
void main()
{
vec3 N = normalize(localPos);
vec3 R = N;
vec3 V = R;
const uint SAMPLE_COUNT = 1024u;
float totalWeight = 0.0;
vec3 prefilteredColor = vec3(0.0);
for(uint i = 0u; i < SAMPLE_COUNT; ++i)
{
vec2 Xi = Hammersley(i, SAMPLE_COUNT);
vec3 H = ImportanceSampleGGX(Xi, N, roughness);
vec3 L = normalize(2.0 * dot(V, H) * H - V);
float NdotL = max(dot(N, L), 0.0);
if(NdotL > 0.0)
{
prefilteredColor += texture(environmentMap, L).rgb * NdotL;
totalWeight += NdotL;
}
}
prefilteredColor = prefilteredColor / totalWeight;
FragColor = vec4(prefilteredColor, 1.0);
}
우리는 환경을 사전 필터링하고, 각 mipmap 레벨에서 거칠기가 변하는 사전 필터 큐브맵에 결과를 저장합니다. 결과적으로 얻어진 prefilteredColor는 총 샘플 가중치로 나누어집니다. 가중치가 적은 샘플(NdotL이 작은)은 최종 결과에 적게 기여합니다.
Capturing pre-filter mipmap levels
남은 작업은 OpenGL이 환경 맵을 다양한 거칠기 값에 대해 여러 mipmap 레벨에 걸쳐 사전 필터링하도록 하는 것입니다. 이는 사실 조도 맵 장에서 원래 설정을 사용하면 매우 쉽게 할 수 있습니다:
prefilterShader.use();
prefilterShader.setInt("environmentMap", 0);
prefilterShader.setMat4("projection", captureProjection);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_CUBE_MAP, envCubemap);
glBindFramebuffer(GL_FRAMEBUFFER, captureFBO);
unsigned int maxMipLevels = 5;
for (unsigned int mip = 0; mip < maxMipLevels; ++mip)
{
// reisze framebuffer according to mip-level size.
unsigned int mipWidth = 128 * std::pow(0.5, mip);
unsigned int mipHeight = 128 * std::pow(0.5, mip);
glBindRenderbuffer(GL_RENDERBUFFER, captureRBO);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT24, mipWidth, mipHeight);
glViewport(0, 0, mipWidth, mipHeight);
float roughness = (float)mip / (float)(maxMipLevels - 1);
prefilterShader.setFloat("roughness", roughness);
for (unsigned int i = 0; i < 6; ++i)
{
prefilterShader.setMat4("view", captureViews[i]);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0,
GL_TEXTURE_CUBE_MAP_POSITIVE_X + i, prefilterMap, mip);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
renderCube();
}
}
glBindFramebuffer(GL_FRAMEBUFFER, 0);
이 과정은 조도 맵 컨볼루션과 비슷하지만, 이번에는 framebuffer의 크기를 적절한 mipmap 크기에 맞게 조정합니다. 각 mip 레벨은 크기가 2배씩 줄어듭니다. 또한, glFramebufferTexture2D의 마지막 파라미터에서 렌더링할 mip 레벨을 지정하고, 사전 필터링할 거칠기를 사전 필터 쉐이더에 전달합니다.
이렇게 하면 사전 필터링된 환경 맵이 적절하게 생성되며, 높은 mip 레벨에서 접근할수록 더 흐릿한 반사를 반환하게 됩니다. 만약 사전 필터링된 환경 큐브 맵을 스카이박스 쉐이더에서 사용하고, 첫 번째 mip 레벨 위에서 강제로 샘플링한다면 다음과 같이:
vec3 envColor = textureLod(environmentMap, WorldPos, 1.2).rgb;
원래 환경의 흐릿한 버전처럼 보이는 결과를 얻을 수 있습니다.

만약 결과가 원래 환경 맵의 흐릿한 버전처럼 보인다면, HDR 환경 맵을 성공적으로 사전 필터링한 것입니다. 다양한 mipmap 레벨을 조절하여 사전 필터 맵이 어떻게 점차 선명한 반사에서 흐릿한 반사로 변하는지 실험해 보세요.
Pre-filter convolution artifacts
현재의 사전 필터 맵은 대부분의 경우에서 잘 동작하지만, 시간이 지나면 사전 필터 컨볼루션과 직접적으로 관련된 몇 가지 렌더링 아티팩트를 마주하게 될 것입니다. 여기에서 가장 일반적인 문제와 그 해결 방법을 소개하겠습니다.
Cubemap seams at high roughness
거친 표면을 가진 물체에서 사전 필터 맵을 샘플링하면, 일반적으로 사전 필터 맵의 낮은 mip 레벨에서 샘플링하게 됩니다. 그러나 OpenGL은 기본적으로 큐브맵의 면 사이에서 선형 보간을 수행하지 않습니다. 낮은 mip 레벨일수록 해상도가 낮아지고, 사전 필터 맵이 훨씬 더 넓은 샘플 로브로 컨볼루션되기 때문에 큐브맵의 면 사이에서 필터링이 부족한 문제가 더욱 뚜렷하게 드러납니다.

다행히도, OpenGL은 GL_TEXTURE_CUBE_MAP_SEAMLESS를 활성화하여 큐브맵의 면 사이에서 올바르게 필터링할 수 있는 옵션을 제공합니다.
glEnable(GL_TEXTURE_CUBE_MAP_SEAMLESS);
애플리케이션의 시작 부분에서 이 속성을 활성화하기만 하면 큐브맵의 솔기(seam) 문제가 사라집니다.
Bright dots in the pre-filter convolution
스펙큘러 반사에서 고주파 세부 요소와 크게 변동하는 광 강도로 인해, 스펙큘러 반사를 컨볼루션할 때 HDR 환경 반사의 변동성을 제대로 반영하려면 매우 많은 샘플이 필요합니다. 이미 상당히 많은 샘플을 사용하고 있지만, 일부 환경에서는 거친(mip 레벨이 높은) 표면에서 여전히 충분하지 않을 수 있으며, 이 경우 밝은 영역 주변에 점무늬 패턴이 나타나기 시작할 수 있습니다.

한 가지 방법은 샘플 수를 더욱 늘리는 것이지만, 모든 환경에서 충분하지 않을 수 있습니다. Chetan Jags의 설명에 따르면, 이러한 아티팩트를 줄이는 방법은 (프리 필터 컨볼루션 동안) 환경 맵을 직접 샘플링하는 것이 아니라, 적분의 PDF와 거칠기에 따라 환경 맵의 mip 레벨을 샘플링하는 것입니다.
float D = DistributionGGX(NdotH, roughness);
float pdf = (D * NdotH / (4.0 * HdotV)) + 0.0001;
float resolution = 512.0; // resolution of source cubemap (per face)
float saTexel = 4.0 * PI / (6.0 * resolution * resolution);
float saSample = 1.0 / (float(SAMPLE_COUNT) * pdf + 0.0001);
float mipLevel = roughness == 0.0 ? 0.0 : 0.5 * log2(saSample / saTexel);
환경 맵의 mip 레벨을 샘플링하려면 삼선형(trilinear) 필터링을 활성화하는 것도 잊지 마세요.
glBindTexture(GL_TEXTURE_CUBE_MAP, envCubemap);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
또한, 큐브맵의 기본 텍스처를 설정한 후 mipmap을 생성해야 합니다.
// convert HDR equirectangular environment map to cubemap equivalent
[...]
// then generate mipmaps
glBindTexture(GL_TEXTURE_CUBE_MAP, envCubemap);
glGenerateMipmap(GL_TEXTURE_CUBE_MAP);
이 방법은 매우 효과적이며, 거친 표면에서 프리 필터 맵의 점무늬 아티팩트를 대부분 제거할 수 있습니다.
Pre-computing the BRDF
미리 필터링된 환경이 설정되었으므로, 이제 두 번째 부분인 분할 합 근사화인 BRDF에 집중할 수 있습니다. 먼저 스펙큘러 분할 합 근사화를 간략히 다시 살펴봅시다:
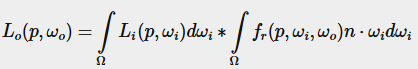
우리는 미리 필터 맵에서 다양한 거칠기 수준에 대해 분할 합 근사의 왼쪽 부분을 미리 계산했습니다. 오른쪽 부분은 BRDF 방정식을 각도 n⋅ωo, 표면 거칠기, 그리고 프레넬의 F0에 대해 컨볼루션해야 합니다. 이것은 스펙큘러 BRDF를 고체 흰색 환경 또는 1.0의 일정한 복사율 Li와 통합하는 것과 유사합니다. BRDF를 3개의 변수에 대해 컨볼루션하는 것은 조금 과하지만, 우리는 F0를 스펙큘러 BRDF 방정식에서 밖으로 빼낼 수 있습니다:
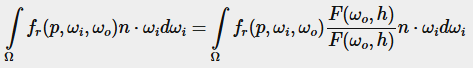
여기서 F는 프레넬 방정식입니다. 프레넬 분모를 BRDF로 옮기면 다음과 같은 동등한 방정식이 됩니다:
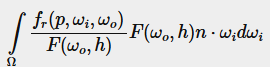
오른쪽에 있는 F를 프레넬-슐릭 근사로 대체하면 다음과 같습니다:
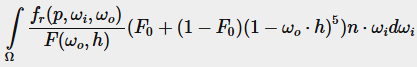
(1−ωo⋅h)5를 α로 바꾸어 F0를 풀기 쉽게 만듭니다:
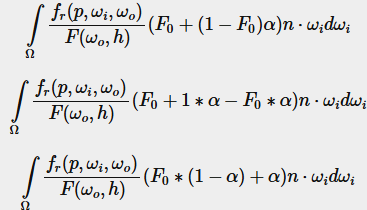
그런 다음 프레넬 함수 F를 두 개의 적분으로 나눕니다:-
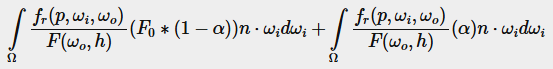
이렇게 하면 F0가 적분 내에서 일정하게 되어 F0를 적분 밖으로 뺄 수 있습니다. 그다음 α를 원래 형태로 되돌리면 최종 분할 합 BRDF 방정식이 나옵니다:
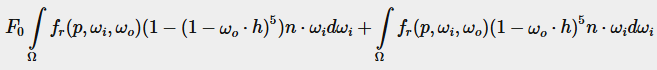
두 개의 결과 적분은 각각 F0에 대한 스케일과 바이어스를 나타냅니다. fr(p,ωi,ωo)에는 이미 F 항이 포함되어 있기 때문에 이 둘은 서로 취소되어 F가 fr에서 제거됩니다.
이전의 컨볼루션된 환경 맵과 유사한 방식으로, 우리는 BRDF 방정식을 그 입력 값들(각도 n과 ωo, 그리고 거칠기)에 대해 컨볼루션할 수 있습니다. 우리는 이 컨볼루션 결과를 2D 룩업 텍스처(LUT)인 BRDF 적분 맵에 저장한 후, 나중에 PBR 조명 셰이더에서 사용하여 최종적으로 컨볼루션된 간접 스펙큘러 결과를 얻습니다.
BRDF 컨볼루션 셰이더는 2D 평면에서 작동하며, 그 2D 텍스처 좌표를 BRDF 컨볼루션의 입력(NdotV와 거칠기)으로 사용합니다. 컨볼루션 코드는 미리 필터링된 컨볼루션과 매우 유사하지만, 이제 BRDF의 기하학적 함수와 프레넬-슐릭 근사에 따라 샘플 벡터를 처리합니다.
vec2 IntegrateBRDF(float NdotV, float roughness)
{
vec3 V;
V.x = sqrt(1.0 - NdotV*NdotV);
V.y = 0.0;
V.z = NdotV;
float A = 0.0;
float B = 0.0;
vec3 N = vec3(0.0, 0.0, 1.0);
const uint SAMPLE_COUNT = 1024u;
for(uint i = 0u; i < SAMPLE_COUNT; ++i)
{
vec2 Xi = Hammersley(i, SAMPLE_COUNT);
vec3 H = ImportanceSampleGGX(Xi, N, roughness);
vec3 L = normalize(2.0 * dot(V, H) * H - V);
float NdotL = max(L.z, 0.0);
float NdotH = max(H.z, 0.0);
float VdotH = max(dot(V, H), 0.0);
if(NdotL > 0.0)
{
float G = GeometrySmith(N, V, L, roughness);
float G_Vis = (G * VdotH) / (NdotH * NdotV);
float Fc = pow(1.0 - VdotH, 5.0);
A += (1.0 - Fc) * G_Vis;
B += Fc * G_Vis;
}
}
A /= float(SAMPLE_COUNT);
B /= float(SAMPLE_COUNT);
return vec2(A, B);
}
// ----------------------------------------------------------------------------
void main()
{
vec2 integratedBRDF = IntegrateBRDF(TexCoords.x, TexCoords.y);
FragColor = integratedBRDF;
}
위 코드에서 볼 수 있듯이, BRDF 컨볼루션은 수학을 코드로 직접 변환한 것입니다. 각도 θ와 거칠기를 입력으로 받아 중요도 샘플링을 통해 샘플 벡터를 생성하고, 이를 기하학적 함수와 프레넬 항을 통해 처리하여 F0에 대한 스케일과 바이어스를 계산한 후, 마지막에 평균을 구하여 반환합니다.
이전에 이론 장에서 설명했듯이, BRDF의 기하학적 항은 IBL(이미지 기반 조명)과 함께 사용할 때 약간 다르게 해석됩니다. 그 이유는 k 변수의 해석이 다르기 때문입니다:
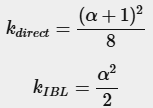
BRDF 컨볼루션이 스펙큘러 IBL 적분의 일부이므로, Schlick-GGX 기하학 함수에서는 kIBL을 사용합니다:
float GeometrySchlickGGX(float NdotV, float roughness)
{
float a = roughness;
float k = (a * a) / 2.0;
float nom = NdotV;
float denom = NdotV * (1.0 - k) + k;
return nom / denom;
}
// ----------------------------------------------------------------------------
float GeometrySmith(vec3 N, vec3 V, vec3 L, float roughness)
{
float NdotV = max(dot(N, V), 0.0);
float NdotL = max(dot(N, L), 0.0);
float ggx2 = GeometrySchlickGGX(NdotV, roughness);
float ggx1 = GeometrySchlickGGX(NdotL, roughness);
return ggx1 * ggx2;
}
여기서 k는 a를 매개변수로 사용하지만, 다른 해석에서와 같이 roughness를 제곱하지 않는 점에 유의해야 합니다. 아마도 a가 이미 제곱된 상태이기 때문에 이렇게 처리된 것으로 보입니다. 이는 Epic Games 측의 불일치일 수도 있고, 원래의 Disney 논문의 방식일 수도 있습니다. 그러나 거칠기를 직접 a로 변환하는 방식은 Epic Games의 버전과 동일한 BRDF 적분 맵을 제공합니다.
마지막으로, BRDF 컨볼루션 결과를 저장하기 위해 512x512 해상도의 2D 텍스처를 생성합니다:
unsigned int brdfLUTTexture;
glGenTextures(1, &brdfLUTTexture);
// pre-allocate enough memory for the LUT texture.
glBindTexture(GL_TEXTURE_2D, brdfLUTTexture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RG16F, 512, 512, 0, GL_RG, GL_FLOAT, 0);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
여기서 Epic Games의 권장 사항에 따라 16비트 정밀도 부동 소수점 포맷을 사용합니다. 또한, 가장자리가 샘플링되는 아티팩트를 방지하기 위해 텍스처의 래핑 모드를 GL_CLAMP_TO_EDGE로 설정해야 합니다.
그런 다음, 동일한 프레임버퍼 객체를 재사용하여 NDC 스크린 공간의 쿼드에 대해 이 셰이더를 실행합니다:
glBindFramebuffer(GL_FRAMEBUFFER, captureFBO);
glBindRenderbuffer(GL_RENDERBUFFER, captureRBO);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH_COMPONENT24, 512, 512);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, brdfLUTTexture, 0);
glViewport(0, 0, 512, 512);
brdfShader.use();
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
RenderQuad();
glBindFramebuffer(GL_FRAMEBUFFER, 0);
이제 분할 합 적분에서 BRDF 컨볼루션 부분을 처리하면 다음과 같은 결과가 나옵니다:

이제, 사전 필터링된 환경 맵과 BRDF 2D LUT이 모두 준비되었으므로, 분할 합 근사를 기반으로 간접 스펙큘러 적분을 재구성할 수 있습니다. 결합된 결과는 간접 또는 앰비언트 스펙큘러 조명으로 작용합니다.